Ollama を Lambda で動かす
みなさんローカルLLMを使っていますか?
私は Ollama をMacBook Proで動かしていたのですが、CPU利用率は全コアほぼ100%、排熱もすごくていつか燃えそうだな、と心配になりました。
ということで、今回はAWS LambdaにOllamaをデプロイしていきます!(この時点でローカルLLMではなくなりますが…)
以下のような前提で進めていきます。
- モデルには Gemma 3 の 1B モデルを使う
- ZIPファイルではLambdaのサイズ上限に引っかかるので、Dockerイメージをデプロイする
Dockerfileの作成
以下が今回使うDockerfileの内容です。
FROM ollama/ollama:0.7.1 AS builder
# gemma3:1bを事前にpullしておく
RUN ollama serve > /dev/null 2>&1 & \
for i in $(seq 1 3); do \
ollama pull gemma3:1b && break || sleep 0.5; \
done && \
pkill -f "ollama serve"
# マルチステージビルドにして、必要なファイルだけをコピーする
FROM ubuntu:24.04
COPY --from=builder /usr/bin/ollama /usr/bin/ollama
COPY --from=builder /root/.ollama /ollama_data
# Lambda Web Adapter
COPY --from=public.ecr.aws/awsguru/aws-lambda-adapter:0.9.1 /lambda-adapter /opt/extensions/lambda-adapter
ENV HOME=/tmp \
OLLAMA_MODELS=/ollama_data/models \
OLLAMA_HOST=0.0.0.0 \
OLLAMA_ORIGINS=* \
PORT=11434 \
AWS_LWA_INVOKE_MODE=response_stream
CMD ["ollama", "serve"]
ポイントは以下の通りです。
- gemma3:1bをDockerイメージに含めるために事前にpullしている
- このとき、ollama serveをバックグラウンドで起動しておく必要がある
- OllamaのDockerイメージ自体が大きいので、Lambdaで動かすのに必要なファイルだけをコピーしている
- Lambda Web Adapterを使って、Lambdaの呼び出しをOllamaへのHTTPリクエストに変換している
- ストリーミングで応答を受けたいので、AWS_LWA_INVOKE_MODE=response_streamを設定している
(Lambda Web Adapterについては Rust (axum) で作った API をコンテナ Lambda としてデプロイする という記事で紹介しています。)
ECRにDockerイメージをpush
ECRに gemma という名前のプライベートリポジトリを作成し、そこにDockerイメージをpushしてください。
基本的にはリポジトリ上に表示されるプッシュコマンドを順に実行すればOKですが、もし
COPY --from=public.ecr.aws/awsguru/aws-lambda-adapter:0.9.1 /lambda-adapter /opt/extensions/lambda-adapter
の部分で403エラーになる場合は、以下のコマンドで回避できます。
aws ecr-public get-login-password --region us-east-1 | docker login --username AWS --password-stdin public.ecr.aws
うまくいくと、以下のような画面になります。
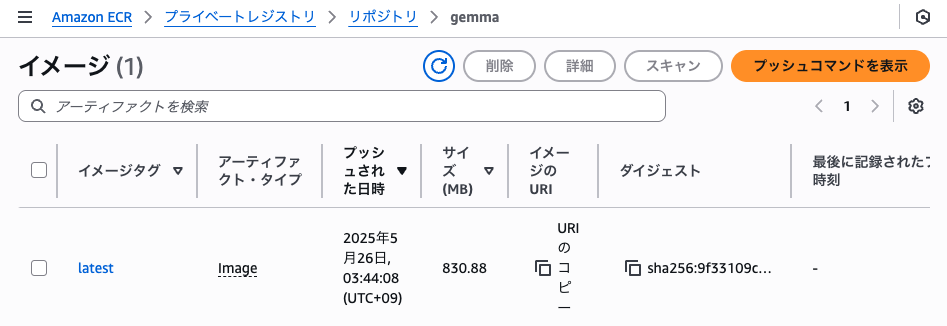
ここでURIのコピーをクリックしておいてください。
Lambda関数の作成
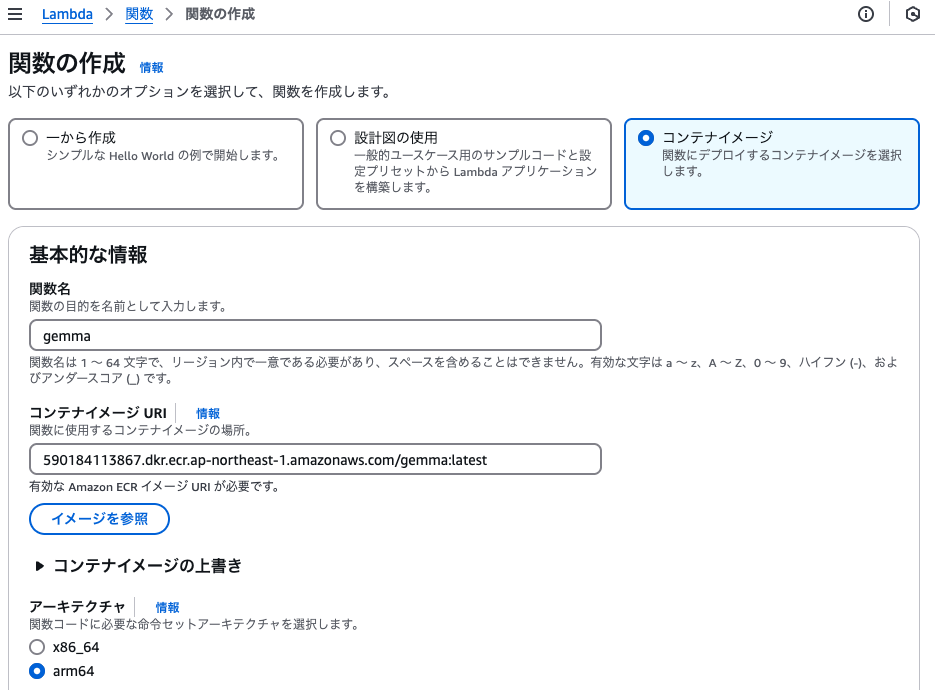
Lambdaのコンソールから、以下の設定で関数を作成します。
- コンテナイメージ を選択
- 関数名: gemma
- コンテナイメージURI: 先ほどECRでコピーしたURIを貼り付け
- アーキテクチャ: お使いのPCがAppleシリコン搭載の方は、必ず arm64 にするのを忘れずに!
次に、設定 > 一般設定を編集します。
- メモリ: 3008MB
- ※デフォルトではこれより大きいメモリは選べず、AWSサポートに問い合わせが必要な場合があります
- タイムアウト: 30秒
最後に、設定 > 関数URL を有効にします。
- 認証タイプ: NONE
- ※テストのために認証なしで呼び出せるようにしています
- その他の設定
- 呼び出しモード: RESPONSE_STREAM
ここで、発行された関数URLをコピーしておいてください。
Gemma 3を呼び出す
以下のチャット画面のOllama URL部分に、先ほどコピーした関数URLを貼り付け、実際にチャットを開始してみてください。
なお、実際のWebサイトとGitHubのソースコードも公開しています(これはGemma 3…ではなくClaude Opus 4が作ってくれました)。
感想・まとめ
LambdaにはGPUがなく、完全にCPUでLLMを動かすことになりますが、想像よりかはサクサク動くなーという印象です。
また、Lambdaのメモリ上限を緩和し10240MBにすると、さらに速く動作させることも可能です。
ただし、イメージが大きいこともあり、コールドスタートが発生すると起動にやや時間がかかるという特徴もあります。
もし興味が湧いたら、パラメータ数やモデル、Lambdaのメモリサイズやタイムアウトを様々に変えて遊んでみて下さい!良きLLM on Lambdaライフを!